Back propagation is a standard method of training Multi Layer Perceptrons. It is by no means the only method of training them, but it does have the advantage of having been proven mathematically correct, i.e. guaranteed to adapt the weights to improve the recognition rate.
In order to carry out Back Propagation, you will need a series of labelled training patterns. These are exemplars which have been labelled so that Back Propagation has a way of knowing which output any given pattern should produce.
The basic steps for Back Propagation are as follows:
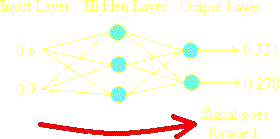
1. The input pattern on which the network is to be trained is presented at the input layer of the net and the net is run normally to see what output it actually does produce.
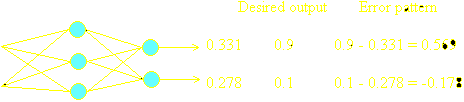
2. The actual output is compared to the desired output for that input pattern. The differences between actual and desired form an error pattern.
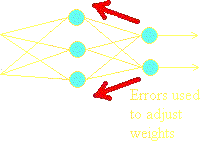
3. The error pattern is used to adjust the weights on the output layer so that the error pattern would be reduced the next time if the same pattern were presented at the inputs.
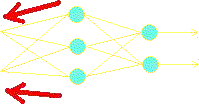
4. Then the weights of the hidden layer are adjusted similarly, this time comparing what they actually produce with the neurons in the output layer to form an error pattern for the hidden layer.
The outline above assumes that there are two layers of neurons. Of course, if there are three (or more) layers, you would add extra steps at the end to train their connection strengths and thresholds. The essential procedure is the same: The signal runs forward through the network, and then error propagates backwards (hence the name) changing the connection strengths and thresholds as it does so.
The network is trained by presenting each input pattern in turn at the inputs and propagating forwards and backward, followed by the next input pattern. Then this cycle is repeated several (many?) times. For instance, if you were training a net to recognise the digits 0 to 9, you would propagate it once on digit 0, followed by one go on digit 1 etc. until you reached 9. Then you would repeat the process many times more, the network getting closer and closer to the required weight values each time. In fact, often a large number of passes through the training data is needed - more than 10,000 possibly - depending on the complexity of the training data, so you may find that you have to leave your neural network training overnight!
The reason that you would train the network on each of the training patterns in turn before repeating the process is to prevent the network becoming too specialised in any particular pattern, i.e. to make sure that it doesn't adjust its weights so as to recognise one pattern well while getting worse at another. It's a bit like learning to play both the piano and violin as a child - you wouldn't spend several years learning the piano before putting it entirely to one side and concentrating entirely on learning the violin. No, you would learn them both together, with piano lessons once a week and violin lessons once a week.
The Back Propagation Procedure itself
Set the weights and the thresholds of all the neurons in the network to small random values, and by "small" I mean in the range 0 to 0.4 (or smaller if you want).
Repeat the following for each "training pattern + desired output for that pattern" pair in the training set:
Present the training pattern to the network and run the network forward to produce some outputs based on the weights as they currently are.
Now we must calculate an error value for the outputs in the output layer, so that we can use that error to adjust the weights and thresholds in the output and previous layes. compare the actual output for each node in the output layer with the desired output for that pattern, and the difference is the error value:
Ei = (ti - ai).ai.(1 - ai)
where Ei is the error for neuron of the output layer, ai is the actual output and ti is the desired output for that neuron for that training pattern. Some of the error values will be positive (where the desired output is greater than the actual output) and some negative. There may even be some zero errors if that particular output turns out to be spot on. Here's some JavaScript code that does the same thing:
var o_error = new Array();
function calculate_output_layer_errors ()
{ for (var i = 0; i < NUM_OUTPUTS; i++)
o_error[i] = (desired_output[i] - o_out[i]) * o_out[i] * (1 - o_out[i]);
}
I have used the o_ convention to denote that these values are associated with the output layer. The array o_out[] holds the outputs from the output layer, and therefore the outputs for the entire network. Note that the errors for the output layer, o_error[] are not local to the function. After all, they will be needed elsewhere.
Now we can use the error values from the output layer to determine the error values for the hidden layer. There is a similar formula to the one above, but in this case, we don't know what the target values should be - after all, they are not defined for going from the hidden layer to the output layer, so we form a weighted sum of the error values from the output layer and use that instead:
Ei = ai.(1 - ai).Sj Ej.wij
In this case, the subscript i refers to the hidden layer, so Ei is the error we are calculating for the hidden layer, ai is the output of neuron i of the hidden layer.
The ai.(1 - ai) part you will recognise from the first formula (for the output layer), but what about the S part? This is a summation of all the error values for the output layer weighted by the weights from the hidden layer to the output layer. Basically, Ej is the error value for output layer neuron j, which is multiplied by the weight from hidden layer neuron i to output layer neuron j, wij, and the Sj symbol means "add these up for all neurons j in the output layer."
Perhaps the code will make this a bit clearer:
var h_error = new Array();
function calculate_hidden_layer_errors ()
{ for (var i = 0; i < NUM_HIDDEN; i++) // Go through entire hidden layer
{ var sum = 0;
for (var j = 0; j < NUM_OUTPUTS; j++) // Sum error values from OP layer
sum += o_error[j] * o_w[i][j];
h_error[i] = h_out[i] * (1 - h_out[i]) * sum;
}
}
Having calculated the errors in the output layer, we can use those to change the weights between the hidden layer and the output layer. We have to calculate all the errors before altering the weights as they are calculated using the old values of the weights. If we alter the weights of the output layer before calculating the errors of the hidden layer, then we are effectively moving the goalposts.
Here is the equation we use:
wij new = wij old + h.Ej.ai
In this case, the subscript i refers to the hidden layer, and j refers to the output layer, so wij is the weight from hidden layer neuron i to output layer neuron j (the weight that we are updating), Ej is the error calculated for neuron j in the output layer, ai is the output from neuron i in the hidden layer, and h is a constant value called the learning rate which scales down any change in the weight value. Typically, h is about 0.01 or 0.025. The larger you make it, the faster the network will learn, but the more prone the weight changes will be to large swings.
What about the threshold of the neuron? That is also a value that has been set to a small random number and needs to be trained. The threshold is treated exactly as if it were a weight from a hidden neuron, except that the "input" from that neuron is taken to be -1 (as the threshold value is subtracted when the neural net is run):
threshold new = threshold old + h.Ej.(-1)
Compare this with the formula just above it for updating the weights. This can be rewritten as follows:
Here is the JavaScript code that does the same thing:
var LEARNING_RATE = 0.025;
function update_output_weights ()
{ for (var j = 0; j < NUM_OUTPUTS; j++) // Go through all output neurons
{ // Process all weights from hidden layer to this output neuron
for (var i = 0; i < NUM_HIDDEN; i++)
o_w[i][j] += LEARNING_RATE * o_error[j] * h_out[i];
// Now train threshold for this neuron
o_thresh[j] -= LEARNING_RATE * o_error[j];
}
}
Finally, we need to train the weights for the hidden layer. In fact, if there are further layers before the hidden layer, the following code should be used to train those as well. The code that follows is pretty much the same as the code directly above, except that the adjustment is based on the value from the input nodes rather than the output of the hidden nodes:
function update_hidden_weights ()
{ for (var j = 0; j < NUM_HIDDEN; j++) // Go through all the hidden nodes
{ // Process all weights from input layer to this hidden layer neuron
for (var i = 0; i < NUM_INPUTS; i++)
h_w[i][j] += LEARNING_RATE * h_error[j] * training_pattern[i];
// Now train threshold for this neuron
h_thresh[j] -= LEARNING_RATE * h_error[j];
}
}
Note, that the weights are based on the elements of the training pattern. If there is an input layer of neurons, then replace training_pattern[i] with i_out[i], and then repeat the training procedure on the input layer (which will, presumably contain training_pattern[i]).
The above procedure constitutes one pass through the training data. Repeat it several times (not the first step about the random values, of course) typically about 1000 to 10,000 times!
The JavaScript code below collects all these functions together into one procedure. It assumes you have a function present_training_pattern(x) which copies training pattern number x to the array training_pattern[] and the desired output for that training pattern to desired_output[]. It also assumes that there are three layers of neurons (i.e. a proper input layer), which is the more general case.